Feature Engineering ( Dimension Reduction, Feature Selection, Feature Extraction )
Feature Engineering 이란?
Feature Engineering은 머신러닝 알고리즘을 작동하기 위해 데이터에 대한 도메인 지식을 활용하여 특징(Feature)를 만들어내는 과정이다. 머신러닝 모델을 위한 데이터 테이블의 컬럼(특징)을 생성하거나 선택하는 작업을 의미한다.
즉, 데이터로부터 목표변수를 위해 설명변수들을 선택, 결합하여 다중공선성을 낮추고 예측, 분류성능이 높은 모델을 만드는 과정이라고 생각한다.
Feature Engineering 방법
Dimension Reduction (차원 축소)
차원 축소는 고차원의 데이터를 저차원으로 축소하는 과정을 말한다. 주어진 데이터의 변수(차원)을 줄이는 작업을 통해 데이터를 더 효율적으로 다룰 수 있다. 차원 축소는 주로 변수의 개수가 많을 때 데이터의 복잡성을 줄이거나 계산 비용을 절감하기 위해 사용된다.
1. Feature Selection (특징 선택)
- 특징 선택의 목적은 부분 집합을 선택하거나, 불필요한 특징을 제거하여 효율적인 데이터 테이블을 만드는 것이다.
- 결과를 예측할 때, 상관이 없는 불필요한 변수들의 수가 많다면 overfitting 을 초래하기 때문에, 이를 방지하기 위하여 특징선택을 한다.
- 장점 : 학습 시간을 줄이고, 모델의 분산을 줄임으로써 더욱 ※ robust하게 학습된다.
- 해당 방법들은 특징 중 몇 개를 없애보고 개선된다면 성능을 확인해보는 방법이며 이것은 대부분의 특징 선택 알고리즘의 기본 동작방식이다.
※ Robust 학습 : 이상치, 노이즈와 같은 잡음이 포함된 데이터에서도 일반화 능력이 뛰어난 모델을 학습한다.
Robust한 학습은 이상치, 잡음이 포함된 데이터에서도 모델이 안정적으로 작동, 정확한 예측 수행하게 만든다.
1 ) Filter method (필터 기법)
통계기법을 사용하여 설몀변수와 목표변수 사이의 상관관계가 높은 변수 위주로 선택, 필터하는 기법으로 무의미한 변수들을 직접 필터링하는 작업이다.
Machine Learning 에서 Best Feature Subset 을 주는 것이 아니라, Feature-Rank 를 보여줌으로써 각 Feature 의 영향력을 알려주는 방법이다. 즉, 해당 모델의 최적화된 변수선택을 하는 것이 아니라, 사용자에게 각 독립변수의 영향력을 알게 도와주는 역할을 한다고 볼 수 있다.
- Filter Method는 아래와 같은 방법이 존재합니다.
- information gain
- chi-square test (카이제곱)
- fisher score
- correlation coefficient
- variance threshold
2) Wrapper method (래퍼 기법)
Machine Learning의 예측 정확도 측면에서 가장 좋은 성능의 Feature Subset 을 뽑아내는 방법이다. Machine Learning 을 진행하면서 Best Feature Subset을 찾아가는 방법이기 때문에 시간과 비용이 매우 높게 발생한다. 하지만 최종적으로 Best Feature Subset을 찾아주기 때문에 모델의 성능을 위해서는 매우 바람직한 방법이다. 물론, 해당 모델의 파라미터와 알고리즘 자체는 완성도가 높아야 제대로 된 Best Feature Subset을 찾을 수 있다.
① Forward Selection (전진 선택법)
전진 선택은 가장 유의미한 특성을 선택해나가는 방식이다. 변수가 없는 상태로 시작하며, 반복할 때마다 가장 중요한 변수, 성능이 좋은 특성을 추가하여 더 이상 성능의 향상이 없을 때까지 변수를 추가한다.

모델에 추가하는 가장 중요한 변수의 기준
- 변수의 p-value 가 가장 작은 변수
- 모델에 선택했을 때, R^2 값을 가장 많이 증가시키는 변수
- 다른 예측 변수에 비해 모델 RSS(Residuals Sum of Squares) 감소량이 가장 크다.
중지 규칙 기준
모델에 추가되지 않은 남아있는 모든 변수들의 p-value 값이 임계값보다 큰 경우 중지 규칙이 충족된다.
중지 규칙 조건을 만족하면 정방향 선택이 종료되고 p-value < threshold 인 변수만을 포함하는 모델을 반환한다.
임계값을 결정하는 방법
- 고정값 ( ex. 0.05, 0.2 )
- AIC(Akaike Information Criterion)에 의해 결정됨
- BIC (Bayesian 정보 기준)에 의해 결정됨
② Backward Elimination (후진 제거법)
후진 제거(Backward elimination)는 무의미한 특성을 제거해나가는 방식이다. 모든 Feature 을 가진 모델에서 시작하여 특성을 하나씩 줄여나가는 방향(Backward)으로 나아간다. 특성을 제거했을 때 가장 성능이 좋은 모델을 선택하며 유의미한 성능 저하가 나타날 때까지 이 과정을 반복한다.
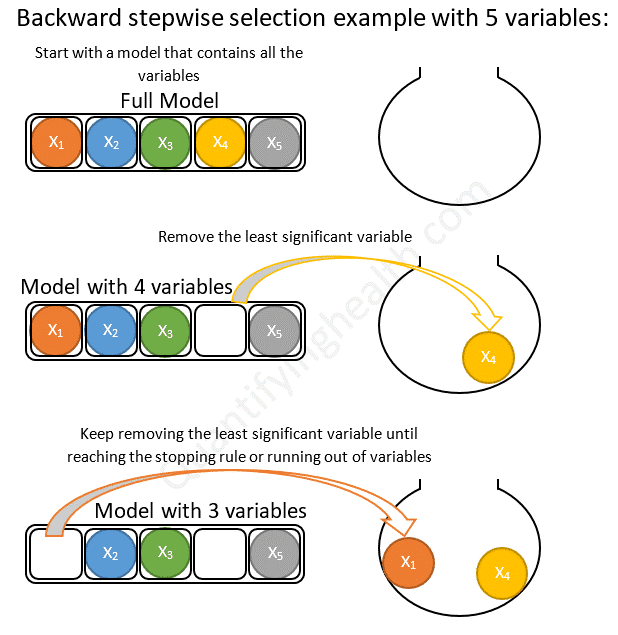
모델에 추가하는 가장 중요한 변수의 기준 (Forward Selection과 반대)
- 변수의 p-value 가 가장 높은 변수
- 모델에서 제거했을 때, R^2 값이 가장 적게 떨어지는 변수
- 다른 예측 변수에 비해 모델 RSS(Residuals Sum of Squares) 가 가장 적게 증가한다
중지 규칙 기준
모델에서 제거되지 않은 모든 변수들의 p-value 값이 임계값보다 작은 경우 중지 규칙이 충족된다.
중지 규칙 조건을 만족하면 후진 제거가 종료되고 현재 단계의 모델이 반횐된다.
임계값 설정 방법은 Forward Selection과 일치한다
③ StepWise Selection (단계적 방법)
전진선택에서 한 번 선택된 특성은 제거되지 않고, 후진 제거에서는 한 번 제거된 특성은 다시 선택되지 않기 때문에 두 방법 모두 더 많은 특성 조합에 대해 모델을 평가할 수 없다는 단점을 가지고 있다.
이를 보완하기 위해 나온 방법인 Stepwise selection(단계적 방법)은 전진 선택과 후진 제거 방식을 매 단계마다 반복하여 적용하는 방식이다. 그렇기 때문에 이전 두 방법보다는 더 오래 걸리지만 최적의 변수 조합을 찾을 확률이 높습니다. Stepwise selection을 시간-성능 그래프에 표시하면 아래와 같이 나타나게 됩니다.

StepWise Selection 단계
1. 변수 입력/제거를 위한 p-value 임계치 설정
2. Forward Selection 을 통한 변수 선정
3. 선택된 변수 중 유의미한 변수를 남기고 제거 (2,3번 반복수행)
4. 변수가 추가되거나 제거할 것이 없는 경우 종료
단계적 선택의 장점과 한계는 해당 링크를 참고하길 바란다.
( 참고 : https://quantifyinghealth.com/stepwise-selection/ )
3) Embedded method ( 임베디드 기법 )
과적합을 줄이기 위해 내부적으로 패널티를 주는 방법으로 릿지, 라쏘 종류로 나뉘어진다. (MSE + L1, L2 규제 항)
정규화를 통하여 가중치(기울기)를 수정, 제한하여 분산을 줄일 수 있다. 하지만 편향성이 증가할 수 있기에 주의해야 한다.
그러므로 적절한 가중치와 편향을 찾아내는 것이 중요하다.

① Ridge Regrssion (릿지 - L2 정규화 항)
릿지 회귀는 MSE가 최소가 되게 하는 가중치(계수)와 편향을 구하고, 규제를 적용하여 가중치의 모든 원소가 0에 가깝게 되도록 만든다. 따라서 변수들을 완전히 제거하지는 않지만 덜 중요한 특성들의 가중치를 줄여 모델을 간소화합니다.

(세타 : 가중치)
② LASSO Regression (라쏘 - L1 정규화 항)
라쏘 회귀는 릿지회귀와 달리 중요도가 떨어지는 원소들의 가중치를 0으로 만들어 특정 변수를 완전히 제거하여 해당 변수가 예측에 전혀 영향을 주지 않게 된다. 따라서 라쏘 회귀는 변수선택 (Feature Selection) 을 하여 특성들을 제거하고 모델을 단순화한다.

③ ElasticNet
Ridge 와 Lasso 를 적절히 사용하여 회귀식을 규제한다.

Ridge, Lasso 모두에 규제의 정도를 조절할 수 있다.
"Lasso 는 상관관계가 있는 다수의 변수들 중 하나를 무작위 선택하여 계수를 축소하는 반면, Elastic-Net은 상관성이 높은다수의 변수들을 모두 선택하거나 제거한다." 라고 합니다...
모두 선택하면 이걸 왜하지..? 제거하는건 Lasso랑 같은 거 같은거고... 여기는 더 공부가 필요해 보인다.
2. Feature Extraction (특징 추출)
- 특징 추출은 원본 특징들의 조합으로 새로운 특징을 생성하는 것이다.
- 고차원의 원본 feature 공간을 저차원의 새로운 feature 공간으로 투영시킨다.
- 새롭게 구성된 feature 공간은 보통은 원본 feature 공간의 선형 또는 비선형 결합이다.
Feature Extraction 방법
1. PCA
2. LDA(Linear Discriminatnt Analysis)
3. PLS(Partial Lease Squares)