4 - 5. Ensemble (Voting, Bagging, Boosting, Stacking), Confusion Matrix
Ensemble (앙상블 방식)
알고리즘 종류에 상관 없이 다양한 머신러닝 모델을 묶어 사용하는 방식
Ensemble 장점
1) 예측성능을 안정적인 향상 가능
2) 모델 파라미터 튜닝이 많이 필요하지 않고 구현이 쉽다
Ensemble 모델 종류

1. Voting
동일한 데이터 세트에 다양한 모델링 결과에 대해 투표하여 최종 결과를 예측

Hard Voting : 각 분류기 결과물에서의 다수결
Soft Voting : 각 분류기의 확률을 평균을 최종 확률로 사용하여 분류한다 (일반적으로 성능 우수)
위 이미지를 예시로 들자면 [0.7, 0.3], [0.2, 0.8], [0.8, 0.2], [0.9, 0.1] 평균인 [0.65, 0.35] 가 최종확률이 되고
더 높은 확률인 최종결과를 1로 예측한다
2. Bagging (bootstrap aggregation)
보팅과 반대로 데이터 세트를 랜덤하게 나누어 학습한 같은 알고리즘 분류기를 결합하여 사용하는 기법 (독립, 병렬)

데이터 셋을 다양한 집합으로 만들어 Data Augmentation 와 유사한 효과를 통해 overfitting을 방지하고 안정적인 성능 제공한다. 즉, Bagging 은 분산(Variance)를 낮추는데 효과적이다.
boostrapping : 다수의 sample dataset을 생성해서 학습하는 방식으로 noise에 대해 robust 하게 된다
Aggregating : 모델의 결정을 합하여 최종 결정
RandomForest
Bagging 기법의 대표예시이자 Decision Tree 집합으로써, 자체적인 Bagging을 통한 학습을 진행
3. Boosting
순차 학습을 하고 예측이 틀린 데이터에 대해서 올바른 예측을 위해 다음 분류기에서 가중치를 update하며 학습을 진행

Weak classifier(분류율이 낮은 모델)에 cascading 하게 연속적으로 수행하여 예측성능 향상시킬 수 있다. 이전 결과를 통해 어떤 sample 이 중요한지 결정하고 weight를 주어 다음 학습에서 사용하여 이전 classifier 결과를 현재 classifier 성능 향상에 사용할 수 있다. 즉, boosting 은 편향(bias) 를 낮추는데 효과적이다
Adaboost(Adaptive Boost)
기존 boosting 발전방식으로, 개별 오류 데이터에 높은 가중치를 주어 다음 학습에 사용

가중치를 증가시킨다면 다음 분류기에서 다시 선택될 확률이 높아지고 더 많이 학습하게 되어 분류 정확도가 올라가게 된다. 이후, 무델들이 분류를 잘한다면 다시 가중치를 감소시킨다.
기존 boosting 에서는 개별 모델 sample data에 동일한 가중치를 주었다면 adaboost는 각 데이터 포인트에 대해 가중치를 부여하여 다음 모델이 그 부분에 더 집중하도록 한다.
GBM (Gradient Boosting Machine)
가중치 업데이트를 경사하강법(Gradient Descent)을 이용하여 최적화된 결과를 얻는 알고리즘입니다.
예측기가 만든 잔여 오차(residual error)에 새로운 예측기를 학습시킵니다.
GBM 장점
- ML 계열의 모델 중 성능이 좋은 편에 속합니다.
GBM 단점
- 과적합이 빠르게 진행될 수 있습니다.
- 하이퍼파라미터 튜닝 노력이 필요합니다.
- 수행시간이 오래걸립니다.
4. Stacking
여러가지 모델들의 예측값을 최종 모델의 학습데이터로 사용하여 예측하는 방법

stacking 과정
1) 여러가지 모델을 이용한 예측값 도출, 옆으로 stack 하여 학습데이터 구축

2) 최종 모델 (=메타 모델)을 통해 최종 예측값 도출
Stacking 은 여러모델 예측 결과 데이터를 바탕으로 메타 학습을 하기 때문에 더 우수한 성능을 보이지만 overfitting 문제가 발생한다. 이를 보안한 것이 Cross-Validation Stacking 이다.
Cross-Validation Stacking
기존 stacking 학습 과정에서 교차검증(Cross validation)을 추가한 모델

CV Stacking 에 대한 이해가 되지 않아서 코드를 참고해서 이해하였다. 너무 복잡하고 어렵게 생각했다.
(참고 : https://huidea.tistory.com/35 )
Confusion Matrix
각 경우에 대해 오차가 얼마나 있었는지 표현하는 방법

True positive rate(TPR) = 실제 : True - 예측: True
True negative rate = 실제 : False - 예측: False
False positive rate(FPR) = 실제 : True - 예측: True
False negative rate = 실제 : True - 예측: True

왜 Confusion - Matrix 가 중요할까??
Unbalanced 데이터세트에서 accuracy 이외에도 precision과 recall 값을 동시에 보아야 제대로 모델성능을 평가 할수 있기 때문에 문제를 잘 이해할 필요성이 있다.

암의 환자를 판정하는 경우에는 정상이라고 판단했으나 실제 암 환자일 확률에 초점을 두어야 하고
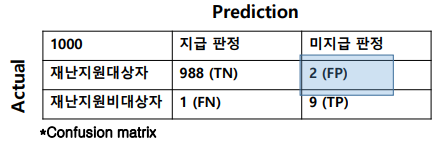
재난지원금대상자 선정과정에서는 미지급 되는 상황에 포커스를 두어야 한다.
ROC Curve
서로 다른 classifier 성능을 측정하는데 사용

추가내용은 이전 포스팅에서 참고 : https://kind-door.tistory.com/6