Linear Model 의 장점
모델이 단순하며 해석 가능성이 있고 다양한 환경에서 일반적으로 안정적인 성능을 제공할 수 있다
Optimizer 종류
0) Normal Equation (벡터연산)
한번에 계산이 되지만 Feature(Dimension)이 늘어남에 따라 복잡도 증가로 인한 비효율성
1) (Batch) Gradient Descent (함수의 변화도가 가장 큰 방향으로 이동)
반복연산이 필요하지만 Feature 개수에 영향 받지 않음 (빅데이터 트렌드에 적합)
단점 : 전체 데이터를 고려하여 기울기를 계산하기 때문에 복잡도가 커지고 학습시간이 오래 걸림
2) Stochastic Gradient Descent (SGD)
전체 데이터를 고려하지 않고 샘플 데이터를 1개씩 계산
단점 : 파라미터 연산하지만 GPU 사용이 불가하고 Noise 에 대한 영향을 많이 받음
3) Mini-Batch Gradient Descent (MSGD, 보편화가 많이 되어있어 "SGD"라고 불리기도 함)
전체 데이터 셋을 여러개의 mini-batch 로 나누어, 한 개의 mini-batch 마다 기울기를 구하고 모델을 업데이트
BGD 와 SGD의 장점만을 가져와 가장 많이 사용됨
BGD보다 Local optimum 에 빠질 확률이 적고 병렬 처리가 유리하다
(참고출처:https://light-tree.tistory.com/133https://light-tree.tistory.com/133)

Gradient Descent Algorithm은 시작점에 따라 지역적인 Local Optimum만을 달성하기 쉽다
이를 방지하기 위해 아레 알고리즘이 발전했다
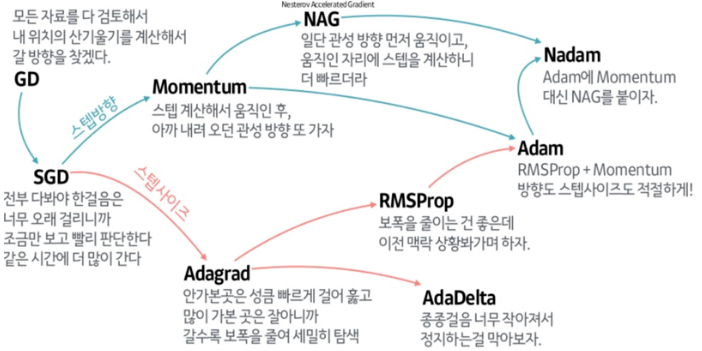
4) Momentum
과거 Gradient 가 업데이트 되어오던 방향 및 속도를 반영하여 현재 위치에서 Gradient가 0이 되더라도 계속해서 학습을 진행할 수 있는 동력을 제공

5) Nesterov Momentum (Nesterov Accelerated Gradient, NAG)
Gradient를 먼저 평가하고 업데이트 (먼저 momentum step 이동 후 actual step 연산)

6) AdaGrad
각 방향의 learning rate를 조절하여 학습 효율 향상

한 방향으로 r 값이 크다는 것은 이미 학습이 많이 진행되었다는 것을 의미한다
> 델타 세타 값은 작아져 수렴속도를 줄인다
단점 : gradient 값이 계속 누적됨에 따라서 step size(=learning rate) 값이 너무 작아져 학습 중지 발생
7) RMSProp
*지수 이동 평균을 사용하여 최근 기울기 값이 더 많이 반영되고 이전 기울기 값이 조금 반영된다
누적 기울기 값(=r)이 무한히 커지지 않아 학습 중지 방지

* 지수이동평균 : 가중변수를 이용하여 최근 수치의 영향력은 높이고 과거 수치의 영향력은 낮추는 것
8) Adadelta
RMSProp 와 유사하지만 학습률, α값 없이 연산
9) Adam (Adaptive moment estimation)
RMSprop + Momentum 결합된 형태
Local optimum을 방지하고 Gradient 크기에 따른 업데이트를 하여 안정성과 효율성 향상
+ 추가)
10) Nadam (Nesterov Accelerated Adaptive Estimation)
Adam 에서 적용한 momentum 기법을 NAG 로 변경하여 더 빠르고 정확한 Local optimum을 찾을 수 있음
11) Radam (Rectified Adam optimizer)
초기 학습 단계에서의 학습률 자동조정함으로써 분산 불안정성 문제를 해결하기 위해 고안되었습니다
이외에도 SWATS, AMSBound, AdaBound 등 발전이 이루어지고 있음
'LG Aimers 요약' 카테고리의 다른 글
| 4 - 5. Ensemble (Voting, Bagging, Boosting, Stacking), Confusion Matrix (0) | 2024.01.22 |
|---|---|
| 4 - 4. Support Vector Machine(SVM), Neural Network (NN), Activation function, Gradient Vanishing (0) | 2024.01.20 |
| 4 - 3. Linear Classification + Loss (Zero-One Loss, Hinge Loss, Cross - Entropy Loss) (0) | 2024.01.19 |
| 4 - 1. Supervised Learning 지도학습 기초 (2) | 2024.01.18 |
| 3. Machine Learning 개론 (2) | 2024.01.18 |



