RNN (Recurrent Neural Networks)
sequence data에 특화된 딥러닝 모델

가중치는 고정한 상태로 h를 다시 입력으로 넣어 반복하는 구조이다

RNN 에서 가장 적합한 활성화함수 tanh 를 사용하여 결과 vector를 만든다
Vanila RNN 모델별 사용예시

- one to many : image captioning
- many to one : sentiment classification
- many to many : machine translation, video classification
Vanila RNN 을 사용한다면 학습 도중에 gradient vanishing 되거나 gradient 가 폭발적으로 증가하여 학습이 불안정한 문제점이 있다. 그래서 기본 구조는 동일하게 유지하되 문제점을 효과적으로 해결한 LSTM(Long short term memory) 나 GRU(Gated recurrent unit) 을 사용한다.
LSTM
이전 정보를 오랫동안 기억할 수 있는 메모리 셀을 가지고 있으며, 이를 통해 긴 시퀀스 데이터를 처리할 수 있습니다.

cell state vector 와 hidden state vector를 통해 입력을 처리하고 인코딩
Seq2seq Model
각 time step 에 해당 vector 가 입력으로 주어져 RNN module이 매 time step 마다 정보를 처리, 축적한다. 문장을 끝까지 읽고 난 후 모든 정보들을 축적하는 과정을 Encoder과정이라고 한다. Decoder 과정에서도 각 RNN module 이 예측을 수행한다. start token이 입력되면 decoder가 실행되고 end token 이 예측될때까지 수행한다. 일반적으로 Encoder와 Decoder 의 RNN모델은 parameter를 공유하지 않는 개별의 모델을 사용한다.

하지만 Encoder 단계에서 output vector가 다시 input vector로 사용되기 위해 RNN hidden state vector의 dimension이 모두 같아야 하는 문제점이 있다. time step이 길어짐에 따라 정보는 많아지지만 정해진 크기 vector에 정보를 압축해서 담는 과정에서 정보를 유실하여 output sequence 에 문제 발생
Seq2seq and Attention Model
decoder 에서 encoder의 마지막 hidden vector만 입력받지 않고 모든 단계 중 필요로 하는 hidden vector 선택하여 에측에 활용. 과거 정보를 유실하고 output sequence 가 제대로 생성되지 않는 문제점 방지할 수 있다.
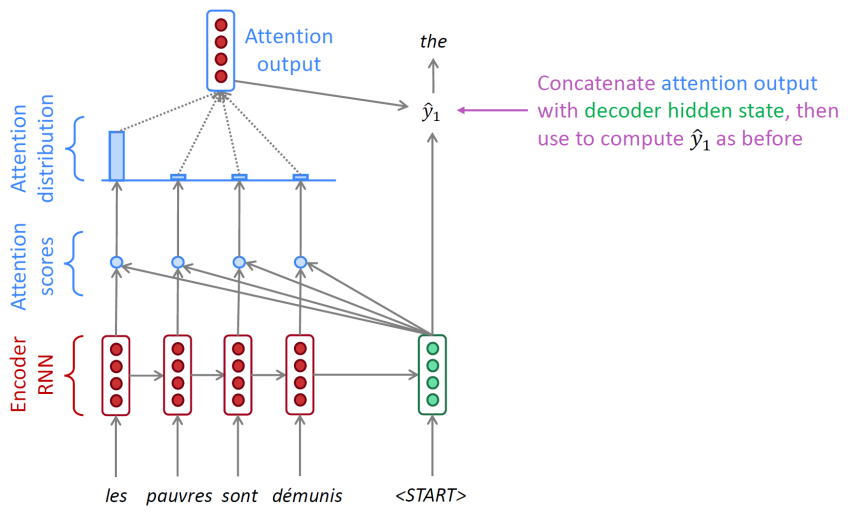
decoder hidden vector가 유일한 입력이 아니라 encoder 모든 단계에서의 hidden vector 도 영향을 미친다. decoder hidden vector 와 4개의 encoder hidden vector 간의 유사도, 내적 값에 softmax를 통과시켜 확률 vector를 얻고 encoder hidden vector에 가중치로 반영하여 그 합을 attention ouput으로 도출하고 추가 입력 vector로 사용한다. 위 사진에서는 attention output 4개, decoder hidden state 4개를 입력으로 사용하여 총 8개의 dimension으로 이루어진 vector 가 입력된다. 이 과정을 통해 다음에 나타날 단어를 더 잘 예측한다.



